Abstract: Stateless Swarm Agent Architecture for Scalable, Privacy-Aligned AI
This paper proposes a novel agentic architecture rooted in swarm principles, designed to enable scalable, stateless, and ephemeral computation for distributed AI systems. Diverging from traditional multi-agent paradigms that rely on persistent state, inter-agent communication, or shared memory contexts, we introduce a model in which agents function as deterministic, testable microservices. Each agent is instantiated transiently to perform a bounded computation over a localized data context—most commonly a vectorized knowledge region—and is immediately terminated upon completion.
The architecture is informed by swarm biology (e.g., eusocial insects) but avoids coordination mechanisms such as synchronization or signaling. Agents are non-communicative, non-persistent, and instead draw from partitioned, geographically distributed vector stores. This minimizes resource overhead, improves computational auditability, and aligns well with privacy-centric deployment models such as those required in medical, legal, and governmental systems.
A critical architectural feature is the dynamic monitoring of vector store entropy and cardinality. Once a local vector region exceeds a threshold (e.g., >6–10 million vectors), it is proactively split into subregions to maintain low-latency semantic access and mitigate conceptual drift. This enables swarms to scale without centralized orchestration while preserving local reasoning accuracy and performance guarantees.
This approach contrasts sharply with monolithic AI pipelines and LLM-in-the-loop architectures by shifting focus from persistent dialogue or memory modeling to stateless, functionally pure transformations. By isolating computation, minimizing shared dependencies, and eliminating memory-based agent identity, this swarm model enables deployment on edge infrastructure, supports compliance in regulated domains, and advances the design of scalable, composable AI reasoning systems.
1. Introduction: The Honeycomb as a Cognitive Model
The honeycomb is a marvel of decentralized structure. It is built cell by cell, with no blueprint and no foreman. Each bee contributes locally—driven by environmental cues, pheromones, and context—yet the result is a highly organized, efficient, and adaptive system.
There is no persistent memory, no individual bee that carries the plan forward. Instead, the structure itself holds continuity. New bees inherit roles from context, not instruction. Cells are built, filled, emptied, and rebuilt—without disrupting the whole.
This emergent, self-maintaining architecture offers a compelling model for collective reasoning. If intelligence can be encoded not in agents but in the structure they briefly inhabit, then cognition becomes a property of the composable space itself.
The system we describe draws inspiration from this biological metaphor. It proposes an agent architecture where ephemeral, memory-light agents interact with a shared vector space—analogous to honeycomb cells—where meaning, memory, and state are distributed across a modular structure rather than stored within persistent entities.
2. Other Natural Models of Distributed Intelligence
Beyond the honeycomb, nature offers other blueprints for scalable, decentralized reasoning. Mycelial networks, for instance, span vast underground systems where no single node directs the whole. Nutrients and signals travel through fungal filaments in response to environmental conditions, creating a living, adaptive mesh. These networks route resources based on need, not command—a principle mirrored in our system’s ability to allocate reasoning agents only where context demands it.
Ant colonies further illustrate this principle of emergent intelligence. An individual ant’s behavior is simple—laying or following pheromone trails—but collective trail dynamics allow the group to discover optimal paths, respond to obstructions, and adapt when priorities change. No ant holds the map. In our architecture, agent swarms exhibit similar properties: agents can self-terminate, duplicate, or reroute based on localized inputs, producing global behavior without central orchestration.
These examples reinforce a central idea: intelligent systems can emerge from structure, flow, and constraints, not from persistent memory or static roles. By modeling computation on these principles, we design AI systems that are more adaptive, ephemeral, and resistant to brittle failure modes—like those seen in rigid monolithic pipelines.
Existing Swarm-Like Architectures: The Case of Google Preview
While the swarm model proposed here is designed to be lightweight, ephemeral, and energy-efficient, it is worth contrasting it with existing large-scale architectures that exhibit superficially swarm-like behavior. A prominent example is Google’s search preview system, which surfaces contextually relevant snippets alongside query results.
Though the front-end experience suggests modular and distributed behavior, these previews are generated by deeply integrated systems operating across mega-scale data centers. Based on public behaviors—such as dynamic snippet generation, entity-aware highlighting, and page fragment summarization—it is reasonable to infer that the underlying system involves:
-
Multi-stage retrieval pipelines combining lexical and semantic matching,
-
Model-based relevance scoring, possibly regionally tuned,
-
On-the-fly summarization agents, generating query-specific previews.
This architecture likely entails stateful coordination, persistent caching, and a global orchestration layer that ensures consistency and speed at planetary scale. The energy and compute cost of maintaining such responsiveness is nontrivial.
In contrast, the swarm agent model proposed here seeks similar functionality through stateless, one-shot agents that run in isolation, do not persist memory, and terminate after contributing their result. These agents are composable but non-hierarchical—designed to operate without upstream or downstream dependency—and can be deployed on edge or local infrastructure. This makes them far more scalable in decentralized environments and ideal for privacy-sensitive, domain-specific vector stores, where mega-infrastructure is neither desirable nor feasible.
Character of the Swarm Model
The swarm model presented in this paper introduces a novel architecture built around hybrid, ephemeral agents that function as stateless, testable microservices. Inspired by the decentralized logic of biological swarms—such as bees contributing to a shared honeycomb—these agents operate independently, without coordination or communication, yet collectively shape and maintain a centralized semantic index (vector store).
Each agent is hybrid in nature, comprising two core functional components:
-
Machine Learning Components: These allow the agent to perform probabilistic reasoning, feature extraction, semantic filtering, or clustering. This component is often powered by LLM embeddings, transformer pipelines, or smaller task-specific models. It handles ambiguity, compression, and dynamic extraction of insights from unstructured or semi-structured data shards.
-
Deterministic Validation Layer: Complementing the learning module is a strict rule-based layer that validates, normalizes, or rejects outputs according to context-specific constraints. This ensures that the contributions made to the shared index are verifiable, auditable, and aligned with system-wide schemas or standards.
Key properties of these swarm agents include:
-
No Upstream or Downstream Dependencies: Agents do not rely on message passing, invocation graphs, or state propagation. Once instantiated, they query a bounded shard of the vector store, perform analysis or synthesis, and submit their contribution—then terminate.
-
Isolated Execution and Testability: Because agents are fully self-contained and stateless, they can be evaluated, replayed, or swapped without altering system behavior. This leads to improved reproducibility and modular development.
-
Elastic Scaling without Coordination Overhead: Agent execution can be scaled horizontally without requiring distributed scheduling or swarm synchronization. Energy use and compute load are tightly bounded, as no memory is propagated and no inter-agent state must be maintained.
Together, these properties define a non-monolithic, composable inference architecture capable of dynamic adaptation to new data while preserving control over validation, consistency, and resource cost. By contributing only vetted updates to the central vector store, each agent serves the broader collective goal without needing awareness of other agents—echoing the biologically distributed intelligence of natural swarms.
Case Study: Extending the Swarm — Repairing and Revealing AI-Generated Images
In the case of generative imagery—such as those produced by Stable Diffusion—the final product is often impressive, but flawed. Hands may emerge with too many fingers, eyes may misalign, or lighting inconsistencies may subtly break the illusion. These are not random errors; they are predictable failure modes.
Now imagine invoking a palette of swarm agents, each trained or fine-tuned to recognize a particular class of visual defect. One agent scans the image for malformed hands. Another inspects for abnormal finger counts. A third analyzes light source consistency. If a flaw is detected, the agent flags or repairs it—either automatically or with human-in-the-loop review. The corrections could be visualized live, like brush strokes in a Photoshop-like UX. The result is not just a prettier image, but a collaborative debugging of the generative process itself.
But here’s the twist: the exact same swarm architecture can run in reverse. Instead of fixing flaws, it highlights them—revealing telltale signs of artificiality. The same agents that clean up a hand can also flag it as likely synthetic. This isn’t just style transfer or upscaling—it’s multi-agent image forensics.
So in a world polarized around AI creativity, where generative images are both tools and threats, the swarm offers a middle path: fix what’s broken—or prove what’s fake.
Medical Knowledge as Honeycomb: A Swarm Model for Structured and Unstructured Health Data
In swarm-based architectures, individual agents serve not as general-purpose crawlers but as precision gatherers. Applied to medical information systems, this model envisions a shared honeycomb — a vector store or indexed knowledge graph — populated by both deterministically sourced data (e.g., from the Physician’s Desk Reference, clinical guidelines) and curated private datasets (from hospitals, research centers, or regulatory filings).
Rather than indiscriminate scraping, agents are tasked with tightly-scoped missions: extract dosage ranges for a new therapeutic, identify contradictions in recent oncology trials, or cross-reference drug interactions by demographic. These agents validate and format findings before depositing them into the honeycomb, where the structure enforces consistency and contextual linkage.
The honeycomb can be queried either through deterministic interfaces (rule-based, field-level search) or through LLM-powered agents that understand medical language and provide
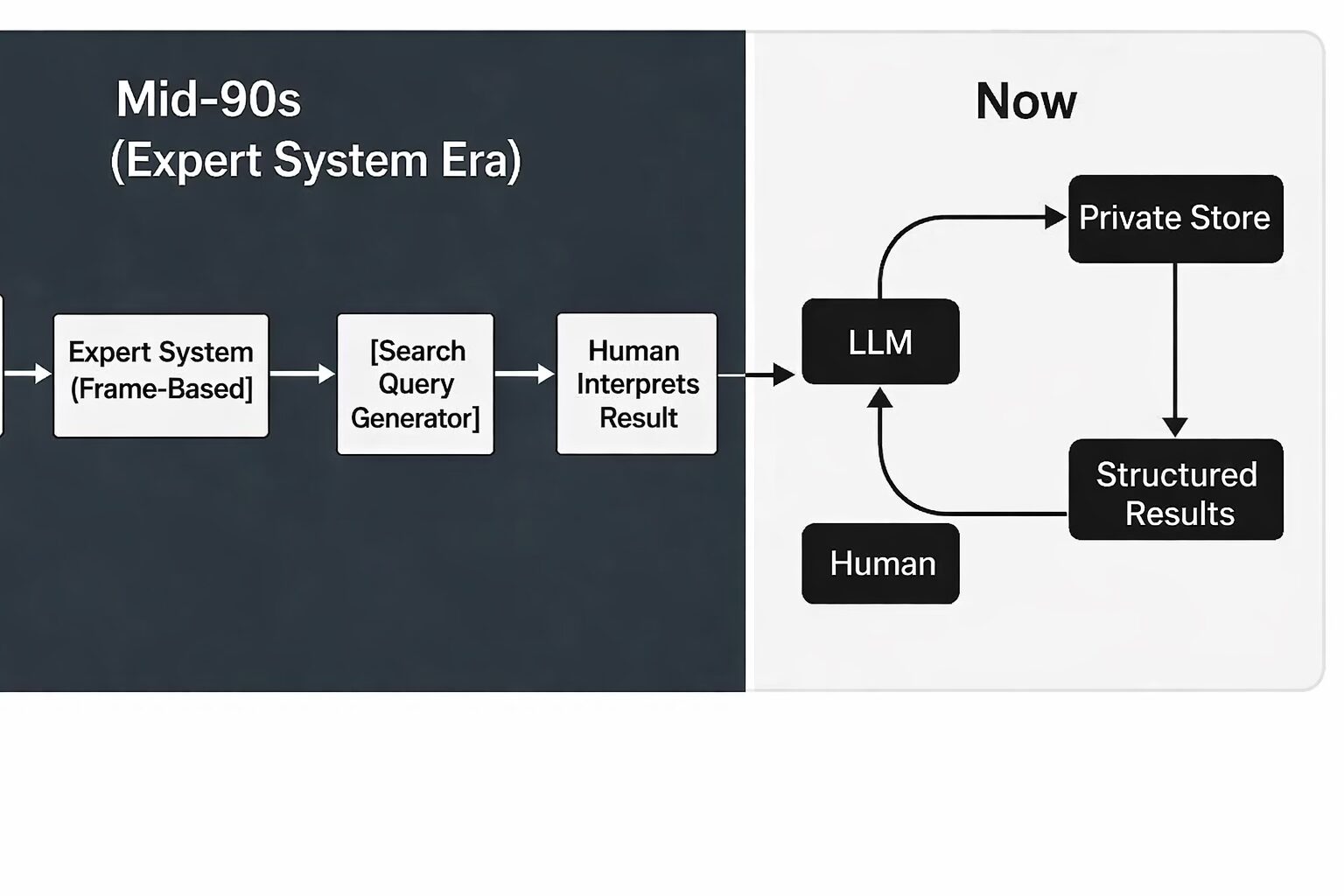
narrative responses. Critically, the swarm is extensible — new agents can be deployed to handle emerging domains (e.g., mRNA platforms or rare diseases), and each agent improves the collective structure rather than duplicating effort.
By tightly coupling deterministic validation with probabilistic language access, this hybrid model offers both reliability and flexibility, with swarm agents acting as disciplined contributors rather than freeform wanderers.
Toward Stateless Resolution via Shared Context
When we initially explored this problem, it appeared that some propagation of reasoning would be required between agent layers—an upstream flow of context or results. However, deeper analysis revealed this was not strictly necessary. Each agent, when designed as an ephemeral reasoning unit, can operate deterministically on its assigned input and deposit its findings into a shared reasoning substrate—what we term the honeycomb, a centralized vector store. Upstream notification is only required in real-time systems where task completion must be observed externally; even then, a simple signal suffices. This shift—from chained reasoning to shared-state resolution—enables a more stateless, composable model of swarm behavior, improving scalability and minimizing inter-agent dependencies.